Sztuczna inteligencja Google Quantum
Firma Google ogłosiła dziś demonstrację kwantowej korekcji błędów w nowej generacji procesorów kwantowych, Sycamore. Nadmiarowość w Sycamore nie jest tak ekscytująca – to ta sama liczba bitów, tylko z lepszą wydajnością. Uzyskanie korekcji błędów kwantowych nie jest tak naprawdę wiadomością – udało im się sprawić, by działała kilka lat temu.
Zamiast tego oznaki postępu są nieco bardziej subtelne. W poprzednich generacjach procesorów kubity były na tyle podatne na błędy, że dodanie ich większej liczby do systemu korekcji błędów powodowało więcej problemów niż wzrost poprawek. W tej nowej iteracji możliwe jest dodanie większej liczby kubitów i zmniejszenie wskaźnika błędów.
Możemy to naprawić
Jednostką funkcjonalną procesora kwantowego jest kubit, czyli wszystko – atom, elektron, blok nadprzewodzącej elektroniki – co może być użyte do przechowywania stanu kwantowego i manipulowania nim. Im więcej masz bitów, tym bardziej wydajna będzie maszyna. Uważa się, że do kilkuset można wykonywać obliczenia, które są trudne do wykonania na tradycyjnych komputerach.
To znaczy przy założeniu, że wszystkie kubity zachowują się poprawnie. A ona generalnie nie. W rezultacie odejmowanie większej liczby kubitów od problemu zwiększa prawdopodobieństwo wystąpienia błędu przed zakończeniem obliczeń. Tak więc mamy teraz komputery kwantowe z ponad 400 kubitami, ale próba wykonania jakiejkolwiek operacji obliczeniowej wymagającej wszystkich 400 kubitów zakończy się niepowodzeniem.
Tworzenie logicznego kubitu korygującego błędy jest ogólnie akceptowane jako rozwiązanie tego problemu. Ten proces tworzenia obejmuje dystrybucję stanu kwantowego w grupie połączonych kubitów. (Z punktu widzenia logiki arytmetycznej wszystkie te kubity sprzętowe można zaadresować jako pojedynczą jednostkę, stąd „kubit logiczny”.) Korekcja błędów jest możliwa dzięki dodatkowym kubitom przylegającym do każdego elementu kubitu logicznego. Można to zmierzyć, aby wywnioskować stan każdego kubitu, który jest częścią kubitu logicznego.
Teraz, jeśli jeden z kubitów sprzętowych, które są częścią kubitu logicznego, ma błąd, fakt, że zawiera on tylko ułamek informacji kubitu logicznego, oznacza, że stan kwantowy nie jest zepsuty. Pomiar jego sąsiadów ujawni błąd i pozwoli na pewną ilościową manipulację, aby go naprawić.
Im więcej kubitów sprzętowych przeznaczysz na kubity logiczne, tym są one potężniejsze. Teraz są tylko dwa problemy. Po pierwsze, nie mamy kubitów do stracenia. Uruchomienie solidnego systemu korekcji błędów na procesorach o największej liczbie kubitów wymagałoby użycia mniej niż 10 kubitów do obliczeń. Drugi problem polega na tym, że współczynniki błędów kubitów sprzętowych są zbyt wysokie, aby którykolwiek z nich mógł działać. Dodanie istniejących kubitów do kubitu logicznego nie zwiększa jego możliwości; Zwiększa to prawdopodobieństwo popełnienia zbyt wielu błędów jednocześnie, aby można je było naprawić.
To samo, ale inne
Odpowiedzią Google na te problemy było zbudowanie nowej generacji własnego procesora Sycamore, który miał taką samą liczbę i układ kubitów sprzętowych jak poprzedni. Firma skupiła się jednak na zmniejszeniu wskaźnika błędów poszczególnych kubitów, aby mogły wykonywać bardziej złożone operacje bez doświadczania awarii. Jest to urządzenie używane przez Google do testowania kubitów logicznych z korekcją błędów.
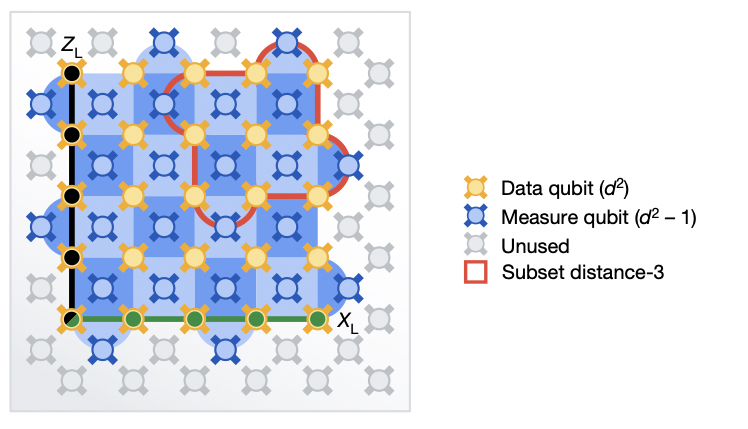
Dwa ustawienia korekcji błędów, z małą wersją podświetloną na czerwono i dużym ustawieniem podświetlonym na niebiesko. W obu zestawieniach występują dane i korekcja błędów.
Sztuczna inteligencja Google Quantum
Artykuł opisuje testy dwóch różnych metod. W obu przypadkach dane były przechowywane na kwadratowej siatce kubitów. Każdy z nich miał sąsiednie kubity, które mierzono w celu przeprowadzenia korekcji błędów. Jedyną różnicą był rozmiar siatki. W jednej metodzie były to trzy kubity na trzy kubity; W drugim było pięć na pięć. Ten pierwszy wymagał łącznie 17 kubitów sprzętowych; Ten ostatni to 49 kubitów, czyli mniej więcej trzy razy więcej.
Zespół badawczy przeprowadził różne pomiary wydajności. Ale podstawowe pytanie było proste: które kubity logiczne mają najniższy poziom błędów? Jeśli błędy dominują w kubitach sprzętowych, można oczekiwać, że liczba kubitów sprzętowych potroi się, aby zwiększyć poziom błędów. Ale jeśli Google Performance wystarczająco zmodyfikuje kubity zoptymalizowane pod kątem sprzętu, większe, bardziej niezawodne mapowanie powinno obniżyć poziom błędów.
Większy plan wygrał, ale był blisko. Ogólnie rzecz biorąc, większy kubit logiczny miał wskaźnik błędów na poziomie 2,914 procent w porównaniu z 3,028 procent dla mniejszego kubitu. Nie jest to duża funkcja, ale po raz pierwszy pokazano taką funkcję. Należy podkreślić, że poziom błędu jest albo zbyt wysoki, aby użyć jednego z tych kubitów logicznych w skomplikowanych obliczeniach. Google szacuje, że wydajność kubitów sprzętowych będzie musiała wzrosnąć o kolejne 20 procent lub więcej, aby zapewnić wyraźną przewagę dużym kubitom logicznym.
W towarzyszącym pakiecie prasowym Google sugeruje, że dojdzie do tego punktu – obsługując pojedynczy kubit logiczny o długiej żywotności – w „2025-plus”. W tym momencie napotkałbyś wiele takich samych problemów, nad którymi obecnie pracuje IBM: jest tylko tyle kubitów sprzętowych, które można zmieścić w chipie, więc jakiś sposób połączenia tak wielu chipów w jedną jednostkę obliczeniową musiałby posortować . Google odmówił podania daty, kiedy przetestuje tam rozwiązania. (IBM wskazuje, że w tym i następnym roku przetestuje różne podejścia.)
Tak więc, żeby było jasne, poprawa korekcji błędów o 0,11 procent, która wymaga prawie połowy procesora Google do obsługi pojedynczego kubitu, nie oznacza żadnego postępu obliczeniowego. Nie jesteśmy bliżej złamania szyfrowania niż wczoraj. Pokazuje jednak, że jesteśmy już w miejscu, w którym nasze kubity są wystarczająco dobre, aby uniknąć pogorszenia sytuacji — i że dotarliśmy tam na długo przed tym, zanim ludziom skończyły się pomysły na poprawę wydajności kubitów sprzętowych. Oznacza to, że jesteśmy bliżej miejsca, w którym przeszkody techniczne, które musimy usunąć, nie mają nic wspólnego z kubitami.
Przyroda, 2023. DOI: 10.1038 / s41586-022-05434-1 (o DOI).

„Muzyk. Guru kawy. Specjalista od zombie. Adwokat mediów społecznościowych. Introwertyk. Ekstremalny miłośnik jedzenia. Ewangelista alkoholu”.